本文共 3592 字,大约阅读时间需要 11 分钟。
spark jupyter
 Many enterprises are faced with the need to expand data processing access to users without impacting mission-critical transactional application environments. The trending approach to this problem is to move the data from these systems of record to a data warehouse. Moving data-at-rest to a mirrored data repository for analytics can yield costly side-effects such as expensive migration workloads, data concurrency and data security. Alternatively, the distillation of data-at-rest to isolate information of interest for downstream analytics can offer optimal results.
Many enterprises are faced with the need to expand data processing access to users without impacting mission-critical transactional application environments. The trending approach to this problem is to move the data from these systems of record to a data warehouse. Moving data-at-rest to a mirrored data repository for analytics can yield costly side-effects such as expensive migration workloads, data concurrency and data security. Alternatively, the distillation of data-at-rest to isolate information of interest for downstream analytics can offer optimal results. 许多企业面临着扩大对用户的数据处理访问权限而又不影响关键任务交易应用程序环境的需求。 解决此问题的趋势是将数据从这些记录系统移至数据仓库。 将静止数据移动到镜像数据存储库以进行分析可能会产生代价高昂的副作用,例如昂贵的迁移工作负载,数据并发性和数据安全性。 或者,通过提取静态数据以隔离感兴趣的信息以进行下游分析,可以提供最佳结果。
IBM宣布 (IBM Announces)
Today, IBM announced the release of the . This enterprise-grade, native z/OS distribution of the open source in-memory analytics engine, enables the analyzing of business-critical z/OS data sources (such as DB2, IMS, VSAM and Adabas, among others) in place — with no data movement.
今天,IBM宣布了的的发布。 这种开放源代码内存分析引擎的企业级本机z / OS发行版本,可以在适当位置分析关键业务z / OS数据源(例如DB2,IMS,VSAM和Adabas等)。没有数据移动。
Designed to simplify the analysis of big data, this no-charge product allows enterprises to ingest data from diverse sources, including systems of record on the z/OS platform, and apply fast and federated large-scale data processing analytics using consistent Apache Spark APIs. By co-locating the data with the distillation and analysis jobs, companies can improve the time to value for actionable insights in a non-intrusive and cost effective manner.
该免费产品旨在简化大数据的分析,使企业能够从各种来源(包括z / OS平台上的记录系统)提取数据,并使用一致的Apache Spark API应用快速联合的大规模数据处理分析。 通过将数据与蒸馏和分析工作一起定位,公司可以以非侵入性和成本有效的方式缩短实现可行见解的价值评估时间。
 GitHub工具 ()
GitHub工具 ()
In conjunction with this product announcement, IBM has created a to promote the development of an ecosystem of tools around Spark on z/OS. IBM has seeded the new organization with two GitHub repositories derived from , namely the and . These tools are centered around a that is aimed at bootstrapping data scientists who lack access to mainframe data stores.
结合此产品公告,IBM创建了一个以促进围绕z / OS上Spark的工具生态系统的开发。 IBM为这个新组织提供了来自两个GitHub存储库,它们是和 。 这些工具以为中心,该旨在引导缺乏对大型机数据存储访问权限的数据科学家。
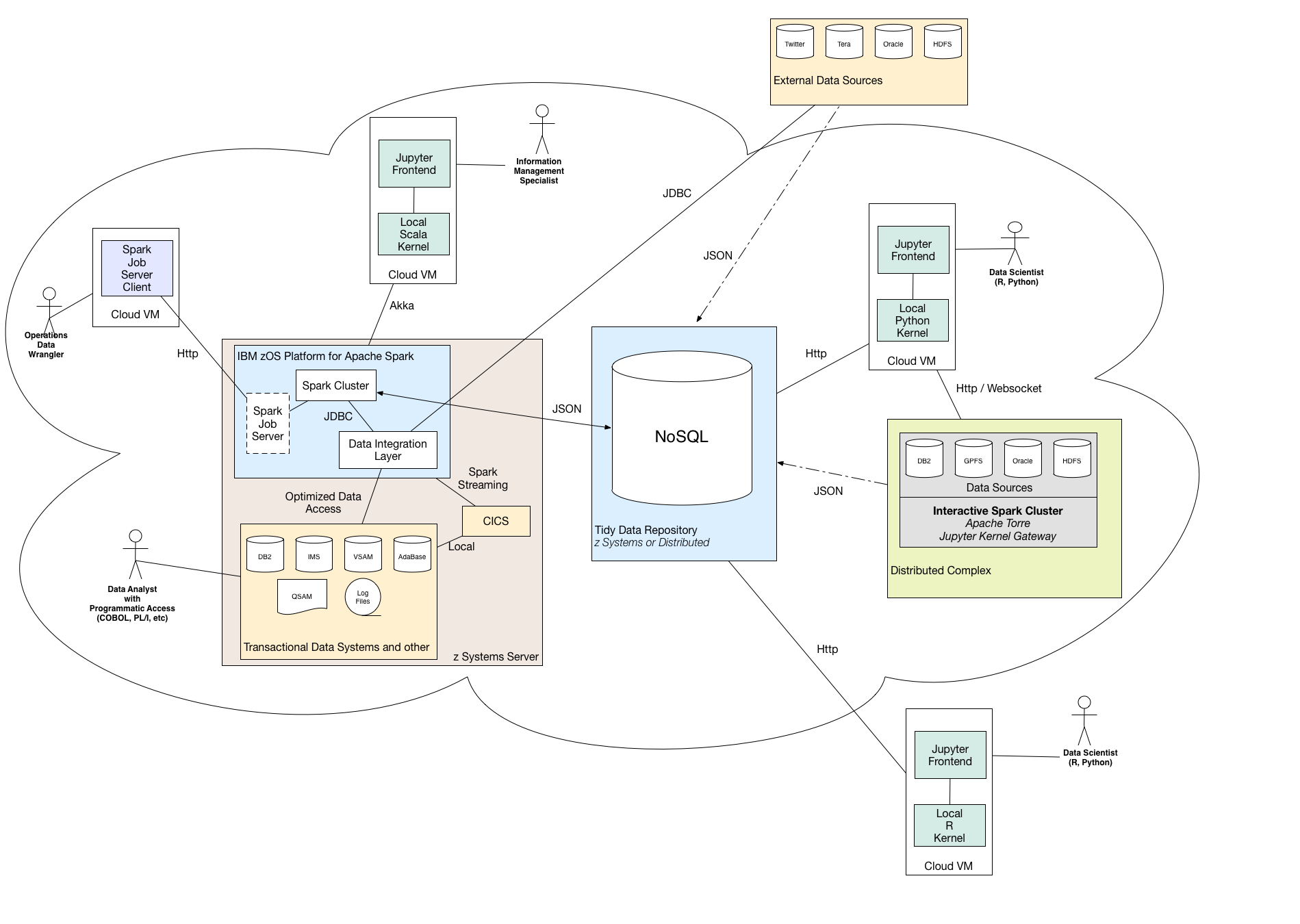
The data wrangler uses the z/OS Platform for Apache Spark to distill and analyze systems of record and then place the results into a NoSQL data repository, conforming to . With the complex task of munging multiple datasets already handled, data scientists can focus their energies on exploratory and predictive analytics using R or Python within a Jupyter notebook. This reference architecture offers a flexible, extensible, and interoperable solution for a variety of use cases. The open source Apache Spark distribution for z/OS, without data abstraction services, can be from DeveloperWorks and deployed using this .
数据管理员使用z / OS Platform for Apache Spark提取和分析记录系统,然后将结果放入符合的NoSQL数据存储库中。 通过处理已经处理的多个数据集这一复杂任务,数据科学家可以在Jupyter笔记本中使用R或Python将精力集中在探索性和预测性分析上。 该参考体系结构为各种用例提供了灵活,可扩展和可互操作的解决方案。 可以从DeveloperWorks 不带数据抽象服务的z / OS的开源Apache Spark发行版,并使用此部署。
下一步 (Next Steps)
The full package, including data abstraction, can be ordered at no-charge from . If you’re really interested in using Spark on the mainframe but feel that you need help getting
可以从免费订购包括数据抽象在内的完整软件包。 如果您真的对在大型机上使用Spark感兴趣,但是觉得需要帮助
Client-facing, strategy and development engineer responsible for architecting, implementing and running next-generation cloud applications on Bluemix, SoftLayer and private clouds.
面向客户的战略和开发工程师,负责在Bluemix,SoftLayer和私有云上设计,实施和运行下一代云应用程序。
翻译自:
spark jupyter
转载地址:http://qzhwd.baihongyu.com/